Introduction
This document discusses configuration management and more specifically a centralized infrastructure which stores sensitive information like usernames, passwords, tokens, TLS certificates, urls endpoints, AWS credentials etc. Configuration management becomes difficult as the application grows and has scaling requirements. This document explores the standards and best practices followed in the industry for implementing stable and secure configuration management solution.
Current State and pitfalls
In most scenarios, we should be concerned about “Secret sprawl” i.e. the distribution of the secrets. A typical configuration setting like database username and password would be used at various places in multiple applications/services. Moreover, there are multiple environments like dev, pre-prod and prod. The entries start multiplying when we need to maintain more than one environment for multiple clients.
The challenges with “secret sprawl” are as follows:
- Location of secrets is not known, it can be on GitHub, it can be on servers as hidden files. Hence it is difficult to track.
- We have limited control on decentralized application. As a service owner if changes a configuration setting, he/she is unaware of the downstream application which might be impacted.
- Breaches cannot be zeroed in easily. Where is it Hardcoded? Or in GitHub? Or in server?
- There is no auditing available. For application and services having compliance and regulatory requirements this is a common pitfall.
Essentially, secret sprawl is all about lack of visibility and control.
Configuration Management Concepts
The desired state of the applications should be as follows:
- Configuration should be decoupled from the application.
- Applications should be built once and deployed everywhere. What changes is configuration which should be injected at runtime.
- Dealing with “secret sprawl”, the basic level answer is centralization. Bring all configuration at one place, make sure that it is strongly auditable, access-controlled and encrypted. Follow good naming conventions for better automation.
- Design application so that it can bootstrap the configuration data from central store injected as environment variables, following 12 factor app best practices.
- Follow convention based approach to reduce the lines of configuration and for better automation and control.
Vault and Configurations
Hashicorp Vault provides a central store for configuration objects. It provides several key benefits as follows:
• Centralized configuration store
• Secrets storage with encryption
• Policy based access to KV pairs
• Auditing capabilities
• Plugin-based architecture for storage and authentication
Architecture of Vault
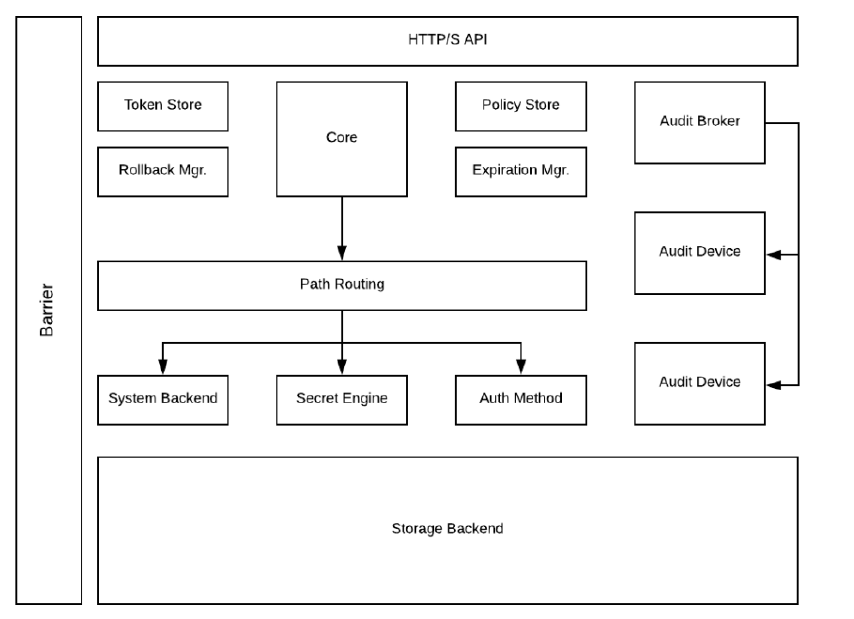
A detailed understanding of the Vault architecture can be viewed in the documentation at the following location.
https://www.vaultproject.io/docs/internals/architecture.html
Some key highlights are:
- Storage and Authentication backends are configurable.
- Consul provides a highly available backend solution recommended by Hashicorp.
- Open-source and docker friendly.
- Power ACL features with token based access which can be restricted to specific keys.
- Barrier ensures end-to-end encryption of all the communication happening from and to the vault.
- Audit device is responsible for managing audit logs. It is recommended to enable audit of the vault at the time of initialization.
- For the first time, the Vault has to be initialized, upon initialization we need to specify the key configuration for Shamir secret sharing.
o Number of keys: The number of keys to split the master key.
o Key Threshold: The number of keys to provide to unseal the vault. - The key configuration should be downloaded and stored in a secure location, should be accessible to only specific group of people.
Architecture of Consul
A typical Consul setup looks likes:
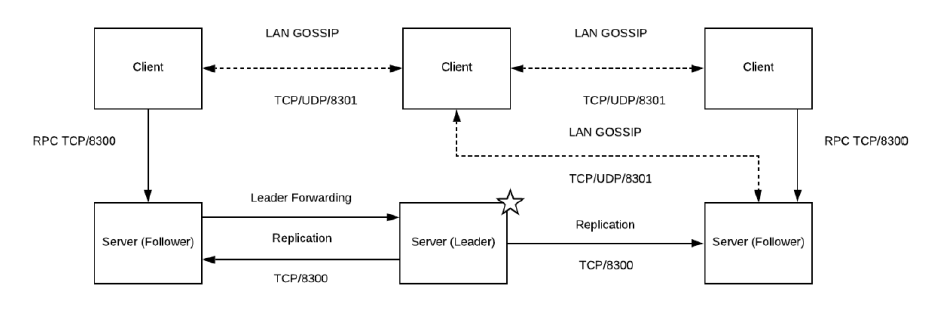
Details can be viewed at https://www.consul.io/docs/internals/architecture.html
Key Highlights:
- Consul agents operate in two modes, client and server, all nodes should run agents in one of these modes.
- Client agents forwards all RPCs to server. They are relatively stateless and take part in LAN gossip protocol.
- Server agents have expanded set of responsibilities, including Raft quorum, maintaining cluster state, responding to RPC queries, WAN gossip in multi-data centers scenarios.
- Visualization to understand Raft quorum. http://thesecretlivesofdata.com/raft
envconsul and hot configuration reload
Along with Vault with Consul backend we will use a tool from Hashicorp called ‘envconsul’. This utility launches a subprocess (application NodeJS/python or any other application) populating the environment variables based on a client configuration.
This utility also watches the configuration on the Consul and Vault and restarts the processes whenever there is an update in configuration entries being watched. We can configure envconsul as a client with restrictive read mode privileges to make sure that a service uses only configuration it is meant to read.
For more information please refer to: https://github.com/hashicorp/envconsul
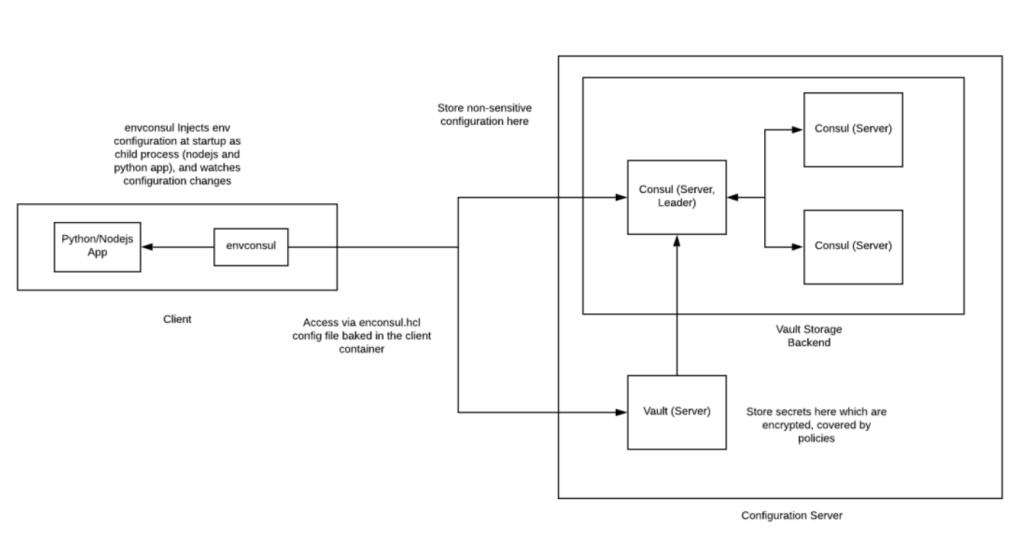
- We setup the Vault (server) with a Consul backend clustered min 3-5 nodes or containers.
- All sensitive secrets are stored via the Vault. Whereas any non-sensitive configuration can be stored in the Consul KV store too. With Consul as storage backed a special entry called as “vault” is created in the Consul KV store which has encrypted configuration contents saved to the Vault.
- The Client application accesses the Consul and Vault using an intermediary application called as ‘envconsul’ which helps injects the application with required environment variables using appropriate client configuration.
- (Optional) alternatively we can also setup a Consul agent running in client mode between for client discovery, health checks ,and other benefits.
- Any change in the configuration watched by envconsul instance on a client would trigger a signal to restart the application and reload fresh configuration.

Setup and Configuration
Refer Setup and Configuration Steps of Valut and Consul in next article.
References,
https://learn.hashicorp.com/vault/operations/production-hardening
https://learn.hashicorp.com/vault/operations/monitoring